
O que são os Modelos de Linguagem de Grande Escala (LLM)?
Os Modelos de Linguagem de Grande Dimensão (LLM) são um tipo de Inteligência Artificial (IA), em particular os Modelos Transformer, que são treinados com um conjunto de dados de texto muito grande e conseguem gerar texto semelhante ao humano. São chamados de «grandes» porque são treinados com um conjunto de dados que contém um grande número de palavras ou caracteres, muitas vezes na ordem dos milhares de milhões. Os modelos de linguagem de grande dimensão são capazes de gerar texto que é difícil de distinguir do texto escrito por humanos, porque aprenderam os padrões e as estruturas da linguagem a partir dos dados com que foram treinados.
Estes modelos têm sido utilizados para uma variedade de tarefas, incluindo tradução, resumo, geração de texto e classificação de texto. Também têm sido utilizados para gerar texto que é difícil de distinguir do texto escrito por humanos, o que suscitou preocupações quanto ao seu potencial uso na geração de notícias falsas ou outros tipos de desinformação.
BERT, GPT-3 e outros
Exemplos de LLM são o BERT, o GPT-3 e o ChatGPT.
O BERT (Bidirectional Encoder Representations from Transformers) é um modelo de representação linguística desenvolvido pela Google, treinado para compreender o contexto e o significado das palavras numa frase, analisando as palavras que as precedem e as que se seguem. É particularmente útil para tarefas de processamento de linguagem natural que exigem a compreensão do contexto em que as palavras são utilizadas, como a resposta a perguntas e a classificação de textos.
O GPT-3 (Generative Pre-trained Transformer 3) é um modelo de geração de linguagem desenvolvido pela OpenAI, treinado para gerar texto semelhante ao escrito por humanos. Pode ser ajustado para uma variedade de tarefas de geração de linguagem, como tradução, resumo e preenchimento de texto. O GPT-3 destaca-se pelo seu grande tamanho, com 175 mil milhões de parâmetros, o que o torna um dos maiores modelos de linguagem já treinados. Tanto o BERT como o GPT-3 têm tido muito sucesso em várias tarefas de processamento de linguagem natural e contribuíram para avanços significativos na área.
Desenvolvido pela OpenAI, o ChatGPT é um protótipo de chatbot de inteligência artificial especializado em diálogo. Utilizando técnicas de aprendizagem supervisionada e por reforço, o chatbot é um modelo de linguagem de grande dimensão. Trata-se de uma versão aperfeiçoada de um modelo da família GPT-3.5 de modelos de linguagem da OpenAI. O ChatGPT foi lançado em novembro de 2022 e tem chamado a atenção pelas suas respostas detalhadas e bem articuladas, embora a sua precisão factual tenha sido alvo de críticas.
Desde o GPT-3, foram desenvolvidos vários modelos de linguagem de grande dimensão, incluindo:
- GPT-4: Esta é a quarta geração do modelo de linguagem GPT e está atualmente a ser desenvolvida pela OpenAI. Espera-se que seja ainda maior e mais potente do que o GPT-3.
- T5 (Text-To-Text Transfer Transformer): Este é outro grande modelo de linguagem desenvolvido pela Google, treinado para realizar várias tarefas de processamento de linguagem natural. Foi treinado para gerar texto semelhante ao escrito por humanos e tem sido utilizado em tarefas como tradução, resumo e classificação de texto.
- RoBERTa (Robustly Optimized BERT Approach): Trata-se de uma variante do modelo BERT desenvolvida pela Facebook AI, concebida para ser mais eficiente e mais fácil de ajustar para tarefas específicas. Tem alcançado resultados de ponta em vários benchmarks de processamento de linguagem natural.
- XLNet (eXtreme Language Network): Trata-se de um modelo de representação linguística desenvolvido pela Google, concebido para captar com maior eficácia as dependências de longo alcance na linguagem. Tem obtido resultados de ponta numa variedade de tarefas de processamento de linguagem natural.
Estes são apenas alguns exemplos dos muitos modelos de linguagem de grande escala que foram desenvolvidos nos últimos anos. Estes modelos têm o potencial de revolucionar uma variedade de aplicações no processamento de linguagem natural e não só.

Qual é a importância dos grandes modelos de linguagem no setor dos seguros?
A utilização de grandes modelos linguísticos no setor dos seguros tem o potencial de revolucionar a forma como as seguradoras operam, além de trazer uma enorme inovação à sua proposta de valor. Na próxima década, estas poderosas ferramentas de aprendizagem automática serão cada vez mais utilizadas para melhorar a precisão e a eficiência dos processos de seguros, levando a melhores resultados tanto para as seguradoras como para os seus clientes.
Subscrição
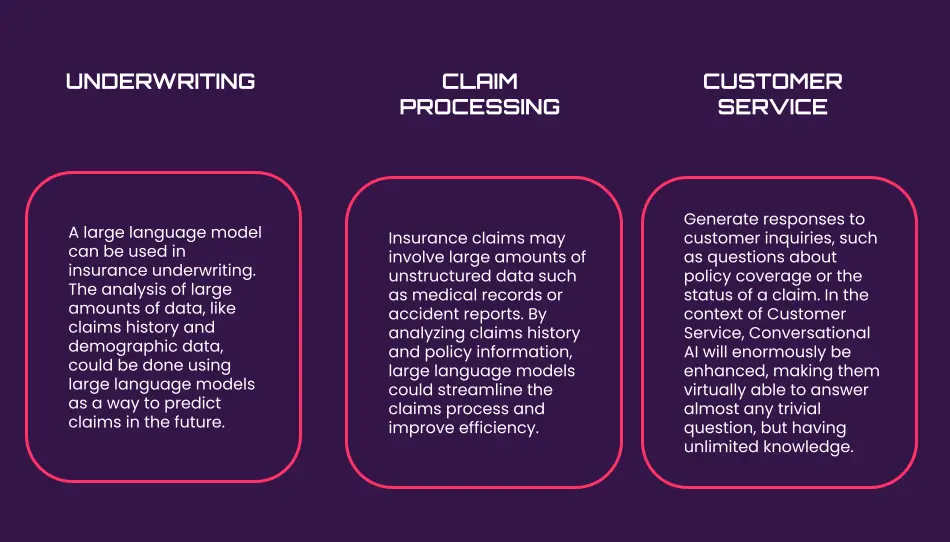
Um modelo de linguagem de grande escala pode ser usado na subscrição de seguros, que é o processo de avaliar o risco envolvido no seguro de uma pessoa ou entidade específica. A análise de grandes quantidades de dados, como o histórico de sinistros e dados demográficos, poderia ser feita usando modelos de linguagem de grande escala como forma de prever sinistros futuros. Usando um conjunto de dados de sinistros de seguros anteriores, um modelo de linguagem de grande escala poderia ser treinado para prever a probabilidade de sinistros futuros para um indivíduo ou empresa específicos. Como resultado, as seguradoras seriam capazes de avaliar com maior precisão o risco associado ao seguro de uma determinada pessoa ou entidade e definir prémios adequados.
Além disso, os grandes modelos de linguagem poderiam ser usados para analisar grandes quantidades de dados não estruturados, incluindo textos de registos médicos ou publicações nas redes sociais, para extrair informações relevantes para a avaliação de riscos.
Se tivesses um assistente que soubesse tudo sobre todos os dados da tua organização, que tivesse lido e memorizado toda a Wikipédia e todos os tipos de fontes de dados relevantes para o teu negócio, que perguntas lhe farias?
Processamento de reclamações
Outra área em que os modelos de linguagem de grande escala terão um impacto significativo é o processamento de sinistros. O processamento de sinistros de seguros pode ser complexo e demorado, especialmente quando envolve grandes quantidades de dados não estruturados, como registos médicos ou relatórios de acidentes. Ao analisar grandes quantidades de dados, como o histórico de sinistros e informações sobre apólices, os modelos de linguagem de grande escala poderiam agilizar o processo de sinistros e melhorar a eficiência.
Para prever a probabilidade de um pedido de indemnização ser aprovado ou recusado, um modelo de linguagem de grande escala poderia ser treinado com um conjunto de dados de pedidos de indemnização anteriores. Desta forma, as seguradoras podem processar os pedidos mais rapidamente e decidir se os aprovam ou recusam. Tal como no caso da subscrição, os grandes modelos linguísticos poderiam ser usados para analisar textos de registos médicos ou relatórios de acidentes, para extrair informações relevantes e classificar os pedidos de indemnização em diferentes categorias. Como resultado, parte do processo de indemnização poderia ser automatizada, reduzindo a necessidade de revisão manual.
É importante notar que, embora os grandes modelos de linguagem tenham potencial para serem ferramentas úteis no processamento de sinistros, devem ser usados em conjunto com outros métodos e não se deve confiar exclusivamente neles. Pensa nisso! A um modelo como este poderia ser feita uma pergunta do tipo «Devo pagar este sinistro?». Ele responderia a essa pergunta com «sim» ou «não», cada uma com um nível de confiança, bem como uma explicação sobre por que e como chegou a essa conclusão. Seria isso revolucionário? Deixo essa conclusão para ti.
Atendimento ao cliente
Os modelos de linguagem de grande escala também têm potencial para serem utilizados no setor dos seguros, com vista a melhorar o atendimento ao cliente. Neste contexto, estes modelos poderiam ser usados para gerar respostas às perguntas dos clientes, como questões sobre a cobertura das apólices ou o estado de um sinistro. Por exemplo, um modelo de linguagem de grande escala poderia ser treinado com um conjunto de dados de consultas anteriores dos clientes e utilizado para gerar respostas adequadas às novas consultas. Isto poderia ajudar as seguradoras a responder de forma mais rápida e precisa às perguntas dos clientes, melhorando a experiência geral do cliente.
Os modelos de linguagem de grande escala também podem ser usados para analisar as consultas dos clientes e classificá-las em diferentes categorias, como perguntas sobre a cobertura das apólices ou consultas sobre sinistros. Isso pode ajudar as seguradoras a encaminhar as consultas dos clientes para o departamento ou agente adequado, para uma resolução mais rápida.
No contexto do atendimento ao cliente, muitas empresas já oferecem soluções de IA conversacional, como chatbots ou voicebots. Estas soluções podem ser enormemente melhoradas por modelos de linguagem de grande escala, tornando-as capazes de responder praticamente a qualquer pergunta trivial, ao mesmo tempo que têm acesso a um conhecimento quase ilimitado. Alguns dos desafios do atendimento ao cliente são a retenção de pessoas e do seu conhecimento, bem como a padronização do atendimento. Isto pode ser alcançado em grande escala com IA Conversacional apoiada por um LLM.
Conclusões
Os modelos de linguagem de grande escala representam um grande passo em direção a uma IA conversacional geral que vai revolucionar a forma como os humanos interagem com as máquinas, mas também a forma como as máquinas compreendem e processam a informação textual. Isto tem, obviamente, um potencial enorme no setor dos seguros, uma vez que grande parte da informação e do conhecimento só está disponível em formato textual.
No entanto, é importante notar que, embora os modelos de linguagem de grande escala tenham potencial para serem ferramentas úteis na subscrição de seguros, no processamento de sinistros e no atendimento ao cliente, devem ser utilizados em conjunto com outros métodos e não se deve confiar exclusivamente neles.
As seguradoras continuarão a precisar de agentes humanos para avaliar pedidos complexos, sinistros ou para ajudar os clientes com questões mais complexas ou subtis. As tarefas mais simples serão tratadas quase na totalidade por sistemas de aprendizagem automática, incluindo grandes modelos de linguagem.
